Agent 是 LLM 和工具组成的系统
当“Agent”越来越像赛博贴金时,我们反而更需要回到它最朴素的工程定义。
在开始之前
2026才刚开了个头,Agent这个词就已经快被说成万能标签了。好像只要一个AI产品不满足于老老实实待在对话框里,而是能多做两步事,就恨不得立刻把Agent贴在自己脸上。
LLM还算好解释,说到底就是大语言模型。可一旦说到Agent,场面就开始变得混乱了。这个词发展到今天,已经越来越像一种赛博贴金,仿佛不管是什么AI产品,只要叫自己Agent,就能立刻显得更高级一点。
但标签喊得再响,也不能代替定义。所以,Agent到底是什么?它和普通的对话式AI,到底差在哪?这才是本文真正想讨论的问题。
一、Agent到底是什么,为什么这个词越来越像营销标签
如果只看现在的互联网语境,Agent这个名词几乎已经是被用烂了,一个会调用日历帮你设定日程的助手叫Agent,一个能搜索网页找资料的聊天框叫Agent,仿佛只要能做的事情不止于聊天,就能往这个词上靠。
但是从工程角度来说,Agent并不是大模型一夜之间长出了手脚,而是一种新的系统形态:让大模型不再止步于对话框中的一问一答,而是接入了检索记忆和工具,与外部环境进行交互,在一个持续循环中完成任务。也就是说,真正重要的不是它会不会说话,而是它能不能根据环境反馈完成任务。
Anthropic在《Building effective agents》里做了一个很有用的区分。他们把这一大类系统统称为agentic systems,但又明确分成两种:一种是workflow,也就是利用大模型的推理能力,将代码中的一些原先难以通过编码算法完成的部分,交由大模型去输出,完成工作;另一种才是更强自治性的agent,由模型自己决定下一步该做什么、调用什么工具、什么时候停下。这个区分非常重要,因为它一下子就把“会调工具”与“真正拥有动态控制权”区分开了。
所以讨论Agent最忌讳的一件事就是把它当成一个模糊的褒义词,他不是”更聪明的AI“,也不是“更听话的助手”。它首先是一个系统设计问题,讨论的核心应该是控制权,反馈回路和执行方式,而不是名字本身。
二、从对话框到行动系统:LLM如何变成Agent
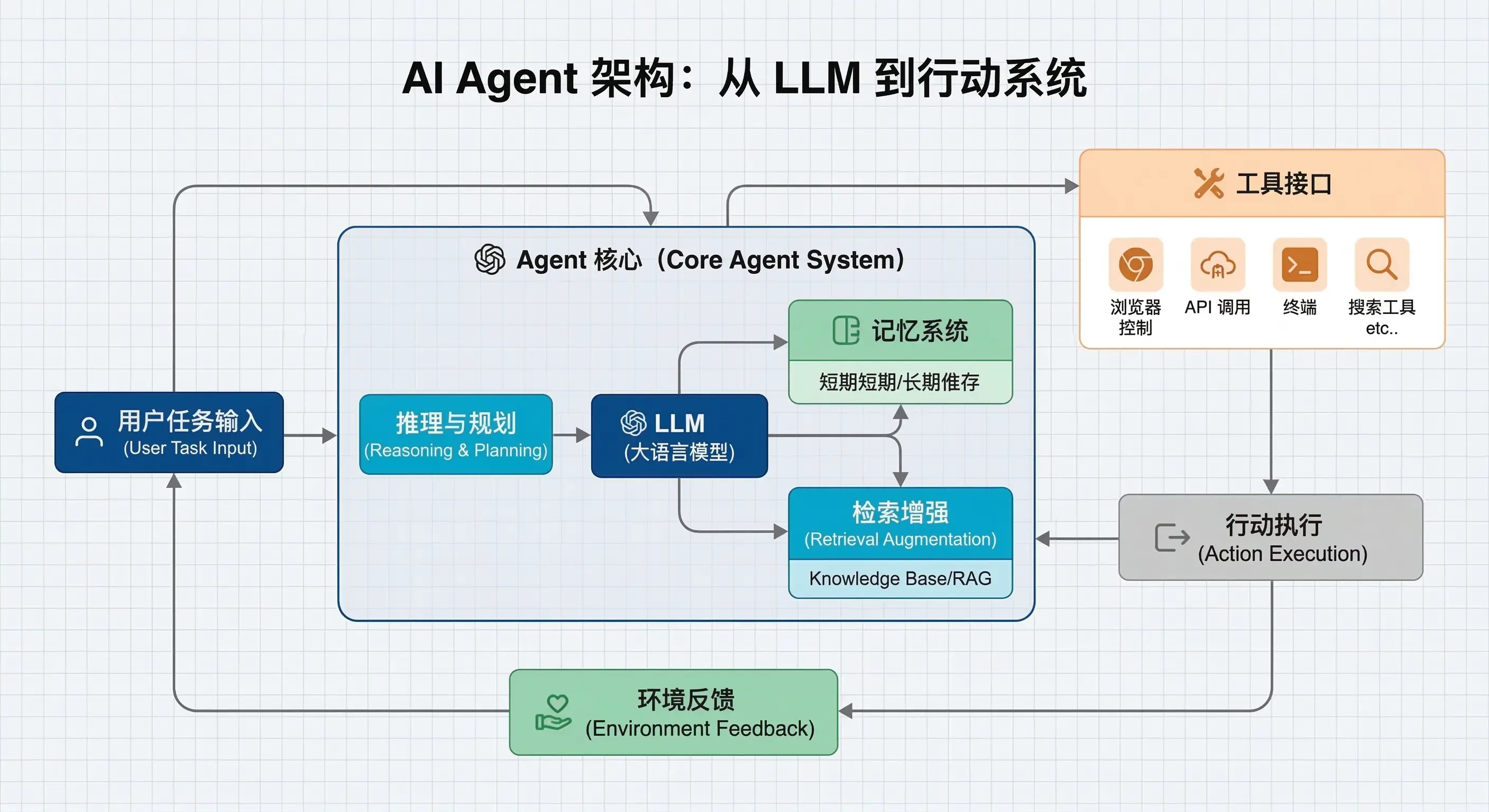
其实把问题拆开来看,所谓Agent,就是一个被增强的LLM。Anthropic给了一个朴素的定义,Agent的核心模块,就是增强型LLM:
The basic building block of agentic systems is an LLM enhanced with augmentations such as retrieval, tools, and memory. Our current models can actively use these capabilities—generating their own search queries, selecting appropriate tools, and determining what information to retain.
智能体系统的基本构建模块是一个经过检索、工具和记忆等增强功能的LLM。我们当前的模型能够主动使用这些功能——生成自己的搜索查询、选择合适的工具,并确定要保留哪些信息。概括来说:Anthropic对Agent的定义其实很朴素:它的核心不是某种神秘的新能力,而是一个被检索、工具和记忆增强过的LLM。模型不只是回答问题,而是能主动查询信息、选择工具、保留状态,并在循环中继续推进任务。
听起来很简单,但是说明了实际上Agent的能力不是凭空长出来的,而是来自非常具体的外接能力:它能不能通过工具获取更多信息,能不能调用浏览器,终端等工具去完成任务,能不能将关键信息记下来,能不能根据环境反馈去自我修正。
一旦这些能力接上,LLM就不再只是回答问题,而是进入到更接近行动的状态。它会先理解用户需求,再决定要不要查资料,要不要拆分任务步骤,要不要调用工具,拿到结果后还要判断是不是继续。到了这一步,系统就已经不只是聊天了,而是在执行任务。
但是并不是说只要增加了工具就值得被称为Agent,也不是说工具就是让大模型更智能的钥匙。在很多场景下,真正有效的还是提示词,RAG和固定流程。Anthropic在文章里反复强调的一点是:不要先想着把系统做复杂,而要先找到最简单、最稳定、最便宜的方案。对于许多应用场景来说,通过提示词和RAG来优化单个LLM调用往往就足够了。
三、Workflow和Agent不是一回事
从架构上看,Workflow和Agent的区别,本质上是谁在控制流程。
如果流程是开发者写死的,比如第一步搜索,第二步清洗,第三步回答,第四步审核,那么这就是Workflow,哪怕里面用了LLM,甚至每一步都用了LLM,但是它本质上还是“代码在指挥模型”。
而Agent不一样,我们只是给Agent环境和若干的工具,模型会根据任务要求和环境反馈,动态决定下一步做什么。可能第一步就去检索,也有可能会先列计划,也可能在流程中发现资料不够,又发起一轮搜索,也可能在某个节点暂停,把选择权交给用户。
看起来只是运行逻辑不同,但实际上会直接影响系统成本,稳定性和可控性,Workflow的优点是稳定,可控,且容易调试,适合步骤明确的任务,而Agent的优点是更灵活,可以处理开放性任务,但代价就是更贵,更慢,而且容易在长任务中积累错误。
我们要理解的不是Workflow更低级,Agent更高级,而是它们适合不同的场景。对于路径明确的任务,Workflow就可以很好的完成任务了,而任务无法提前写出路径时,Agent才有必要出现。
比如“先检索资料,再提取要点,最后生成总结”这种固定链路,就是典型的Workflow。
而如果系统需要根据搜到的内容决定下一步该不该换关键词、要不要追加搜索、是否需要向用户确认方向,这时才更接近 Agent。
四、为什么不是所有AI产品都应该做成Agent
Agent这两年最容易造成的一种错觉,就是它是所有AI产品的自然升级路线。仿佛一个AI如果只停留在一问一答,就是落后,只要能自己分析任务,调用工具,跑循环,立马摇身一变变成Agent,像是未来科技。
但工程上并不是这么回事。Agent解决的,从来都不是“模型不够高级”这个问题,而是“任务路径不可预测,无法写死”的问题。
换句话说,Agent往往不是默认答案,而是一种代价比较高的特殊解法。它更灵活,可以在执行过程中根据环境反馈去不断调整策略,但代价同样明显:更高的token消耗,更长的执行耗时,更复杂的状态管理,以及更难调试的运行状态。一旦系统进入多步循环,问题就不再只是“这一句答得对不对”,而变成“它前面每一步是不是都走对了”。
这也就是为什么不是所有AI产品都适合做成Agent的形态。
对于路径明确的任务,Agent往往没有必要。像是分类,提取,改写,审核这类问题,本身就有清晰的处理流程,更适合用Workflow或者说代码去控制。因为开发者本来就知道下一步应该做什么,没必要把决策权交给模型,让一个本可预测的流程变得不可预测。
对于单轮就能完成的任务,Agent通常也是过度设计。很多问答,知识检索,客服,文案生成之类的服务,往往缺的不是规划能力,而是更好的上下文,更准确的检索,或者更合适的提示词。这类场景中,RAG和普通LLM调用往往就足够了,上Agent只会让系统变得复杂,不一定能获得更好的答案。
而对于高频,低容错的确定性任务,Agent甚至可能是错误的方向。表单处理,权限控制,规则执行,账单计算等,这些任务需要的是稳定,一致,且可审计,而不是临场发挥。
Agent的优势在于灵活,但问题也恰恰处在灵活,当一个系统每次都需要按照同样方式执行时,过多的自治往往会成为风险。
所以,一个AI产品该不该做成Agent,真正的判断标准并不是它听起来高级不高级,而是任务是否真的需要系统在执行过程中,根据外部反馈动态调整路径。
而如果这个任务不仅开放,而且还具有明显的可并行性,单个Agent已经很难在有限上下文里兼顾全部线索时,问题就会进一步升级:这时候,真正值得讨论的就不再是“要不要Agent”,而是“要不要Multi-Agent”。
五、Multi-Agent真正解决了什么问题
如果说前面的问题是“什么场景下才值得上Agent”,那么再往前一步,才轮到Multi-Agent。
很多时候我们会天然觉得,多Agent就是一群Agent在一起干活开会,仿佛一个不够聪明,就多来几个一起想。但从工程的角度来说,事情并没有这么浪漫。多Agent真正解决的不是让系统更像一个团队,而是让任务可以被拆开并行处理。
当一个任务足够开放,信息范围足够宽,单个Agent很难在有限的上下文中兼顾所有方向时,Multi-Agent才开始变得有意义。Anthropic在他们的研究系统里采用的,正是一种典型的orchestrator-worker架构:由一个主Agent负责理解问题,制定策略,拆分方向,再交给多个子Agent并行搜索,最后回传给主Agent做统一整合
这种结构很适合调研或者深度搜索。因为这一类问题往往不是沿着一条规定路径去往下走,而是要同时展开多个线索,最后做比较,归纳汇总。单个Agent当然也能做,但是它本质上是单线程推进,很容易只关注了某一条路径,最后查得很深,但是查得不够全。Multi-Agent的价值就在于它可以多个并行探索分支,换取更高的信息覆盖率。
这并不意味着Multi-Agent是更通用的答案。对于强依赖上下文,步骤之间高度耦合的任务,多Agent往往会变得混乱。尤其是对于修改代码这类问题,多个Agent往往不会更高效,因为他们处理的并不是独立的小块,而是一个互相牵连的完整的系统。
并且,Multi-Agent的token消耗相对来说会更高,按Anthropic在其实践中的经验数据,单Agent的token消耗可能达到普通聊天的约4倍,而Multi-Agent则可能来到约15倍。这也说明多Agent不是白捡性能,而是在用更高的token预算,换取更强的并行探索能力和更高的信息覆盖率。
六、Agent最难的不是“能跑”,而是“可评估”
如果说过去讨论LLM应用,主要集中在提示词和输出质量上,那么到了Agent这里,讨论的事物就彻底变了。Agent的难,不在于它能不能进入循环,也不在于它能不能调用几个工具,而在于你到底知不知道它完成得怎么样,坏的时候又到底坏在了哪里。Anthropic在《Demystifying evals for AI agents》里反复强调,Agent天生比普通单轮模型更难评估,因为它不是一次输出,而是在多轮交互里不断调用工具、修改环境、根据中间结果继续行动,错误也会在这个过程中逐步传播和放大。
这也是为什么,评估Agent不能只盯着最后那句回复。Anthropic在文中专门区分了transcript和outcome:前者是整条执行轨迹,包含推理、工具调用和中间结果,后者则是任务结束后环境里的真实状态。Agent回复一个“任务圆满完成”很简单,但真正重要的不是它说了什么,而是环境数据库里有没有写进去,文件有没有真的改对,外部系统里有没有留下预期结果。到了Agent这里,很多时候“看起来做了”和“实际上做成了”根本不是一回事。
比如一个Agent说自己“已经帮你更新数据库”,这只是transcript里的文本;真正的outcome,是数据库里对应字段是否真的被改了,而且改的是不是目标值。
Anthropic文章里有一个特别值得抄回来的区分,是capabilityeval(能力评估)和regressioneval(回归评估)。前者是在看“这个Agent现在能做好什么”,所以应该设计为很难的任务,甚至可以故意让通过率偏低,给团队留下清晰的爬坡空间;后者问的则是“Agent原来会做的东西,现在是不是还会做”,通过率应该接近100%,因为它的职责不是发现天花板,而是防止系统退化。往往做Agent的时候,最大的问题不是做不出新能力,而是每修一个bug,又顺手把别的地方修坏了,因为本身大模型就不是完全可预测的东西。如果没有regressioneval,这种退化往往只能等到用户反馈才能发现。
所以,Agent开发真正成熟的标志,从来不是它终于能自己跑几圈,而是你开始能稳定地测它、比较它、定位它、迭代它。没有eval的Agent,更像是一个偶尔灵光一现的demo;有了eval,才像是一个能推进的项目。说到底,能跑只是起点,可评估才意味着它真的有资格走向生产环境。
七、今天我们谈Agent,真正该谈的到底是什么
所以今天谈Agent,真正值得谈的,从来不是它像不像人,也不是它会不会自己“思考”,而是我们到底能不能把一个原本只会生成文本的模型,变成一个能调用工具、理解环境、根据反馈调整路径,并且还能被稳定评估的系统。
说到底,Agent不是给LLM换了一个更酷的名字,而是逼着我们重新面对一个更现实的问题:当模型开始行动之后,我们到底该怎么设计它、约束它、评估它。